Testing Phase
Now we have our model which we can use to predict player disposals. Most betting agencies will offer a market
for each game in every round that will include a number of different players. They will set a line for each player
(number of disposals), and the odds for the line. An example of this is as follows:
| Rd No. |
Match |
Player |
Line Over |
Odds Over |
Line Under |
Odds Under |
| 12 |
Melbourne v Sydney |
Clayton Oliver |
31.5 |
$1.90 |
-31.5 |
$1.88 |
| 12 |
Melbourne v Sydney |
Jack Viney |
27.5 |
$1.89 |
-27.5 |
$1.88 |
| 12 |
Melbourne v Sydney |
Callum Mills |
24.5 |
$1.92 |
-24.5 |
$1.79 |
If our model predicts that Clayton Oliver will have a total of 30 disposals for the match, Jack Viney 28 disposals
and Callum Mills 21 disposals, then we would bet on the line under, over and under respecitvely, like so:
| Rd No. |
Match |
Player |
Line Over |
Odds Over |
Line Under |
Odds Under |
Pred. Disposals |
Bet Type |
| 12 |
Melbourne v Sydney |
Clayton Oliver |
31.5 |
$1.90 |
-31.5 |
$1.88 |
30 |
Under |
| 12 |
Melbourne v Sydney |
Jack Viney |
27.5 |
$1.89 |
-27.5 |
$1.88 |
28 |
Over |
| 12 |
Melbourne v Sydney |
Callum Mills |
24.5 |
$1.92 |
-24.5 |
$1.9 |
21 |
Under |
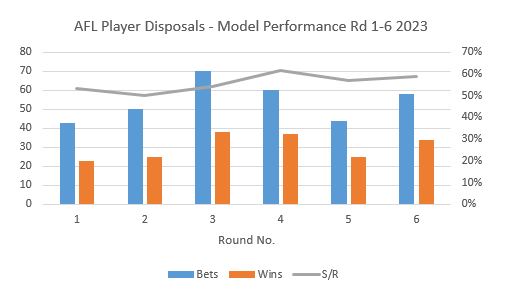
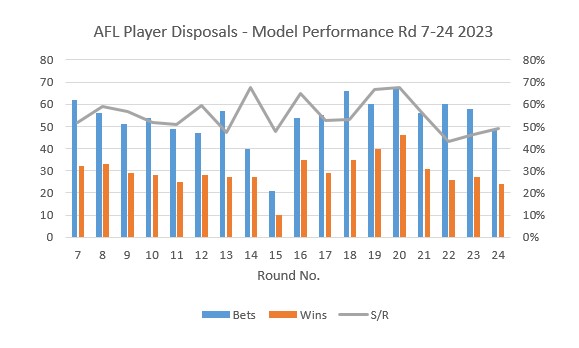
The model was tested over the first six rounds of the 2023 season, producing strong results, with an average strike rate of 56%.
This means that more than half the time, the model is correctly predicting whether or not the number of player disposals will fall under
or over the line offered. But what does this mean when we start to apply this to real world bets?
Break even is generally considered to be around 52-53% (depending on the bookie's market percentage), so with an average strike rate
of 56%, we are well ahead of the market and therefore our model is profitable.
How do we know our model is profitable? Profit in betting is generally referred to as Profit on Turnover or PoT as it is more
commonly known. We can use a very simple formula to convert our strike rate into PoT: